
Atualmente, há uma grande quantidade de dados na Internet. Muitas vezes, é necessário extraí-la e analisá-la para vários fins de investigação de marketing e de tomada de decisões empresariais. Quando necessário, deve ser feito rapidamente e eficientemente.
Por que é que é necessário recolher e analisar dados? Pode ser necessário por uma variedade de razões:
- Realização de uma auditoria no site Web;
- Agregação de dados de lojas online;
- Preparação de conjuntos de treino para redes neuronais;
- Monitorização de críticas em redes sociais, feeds de notícias e blogues;
- Análise do conteúdo do site Web, como a identificação de links mortos no site, etc.
Os dados não se limitam apenas a texto; podem ser imagens, vídeos, tabelas, vários arquivos, etc. Pode ser necessário extrair links e texto, pesquisar por senhas ou frases, recolher imagens, etc.
Outra tarefa vital é monitorar a saúde do site, verificar se não existem links mortos e se o site está geralmente disponível.
Tudo isto requer ferramentas prontas para se utilizar.
Soluções existentes
A abordagem mais comum para recolher e analisar dados é enviar um pedido para um servidor Web, receber e processar a resposta em HTML. Temos de analisar o HTML e extrair as informações necessárias dele.
No entanto, as páginas Web modernas utilizam ativamente o JavaScript e o conteúdo é carregado ou formado dinamicamente em muitas páginas. Não é suficiente apenas obter uma resposta do servidor web — como é talvez apenas uma página inicial com muita execução de JavaScript, que gera o conteúdo necessário.
Como utilizar as capacidades do navegador Web?
Os sites Web são criados para as pessoas. As pessoas visitam os sites Web através dos navegadores Web.
Que tal utilizar o navegador Web para recolher dados? Eliminaria muitas das limitações da abordagem de enviar pedidos para o servidor Web. Afinal, é necessário iniciar sessão em alguns sites e realizar várias ações na página para obter o resultado. Enquanto isso, seria melhor se nós tivéssemos controle sobre o User-Agent do browser, para que o servidor não pense que somos um robô. Também ajuda a receber conteúdos orientados para o ambiente de trabalho, e não apenas uma versão reduzida para dispositivos móveis.
Neste artigo, analisamos a abordagem de coleta de dados utilizando as capacidades de um navegador Web. Em particular, nós recolheremos todos os links no site especificado e verificaremos se há algum deles quebrado, ou seja, links que levam a páginas não disponíveis por qualquer razão. Nós faremos isso usando os recursos do navegador Chromium através da biblioteca JxBrowser.
O JxBrowser é uma biblioteca Java comercial que lhe permite utilizar os poderes do Chromium em aplicações Java comerciais. É útil para empresas que desenvolvem e vendem soluções de software criadas com tecnologia Java ou necessitam de um componente de browser avançado e fiável para aplicações Java criadas para necessidades internas.
O que deve fazer antes de começar?
Quais são os pontos que devemos considerar antes de começarmos a conceber a solução e a escrever o código? Precisamos começar a partir de uma determinada página da Web. O endereço pode ser uma página inicial ou apenas um endereço da Web.
Na página, devemos encontrar links para outras páginas. Os links podem conduzir a outros sites Web (externos) e para páginas do mesmo site Web (internas). Além disso, um link nem sempre conduz a outra página. Alguns deles levam os visitantes para uma seção da mesma página (esses links começam normalmente por um #). Alguns deles não são links propriamente ditos, mas sim atalhos para ações de correio eletrônico - mailto:.
Uma vez que os links podem ser circulares, é necessário ter um cuidado especial. Para lidar corretamente com referências circulares, precisamos recordar as páginas que já visitámos.
É também crucial verificar se a página que o link conduz está indisponível, e é desejável obter um código de erro explicando porque é que está fora do alcance.
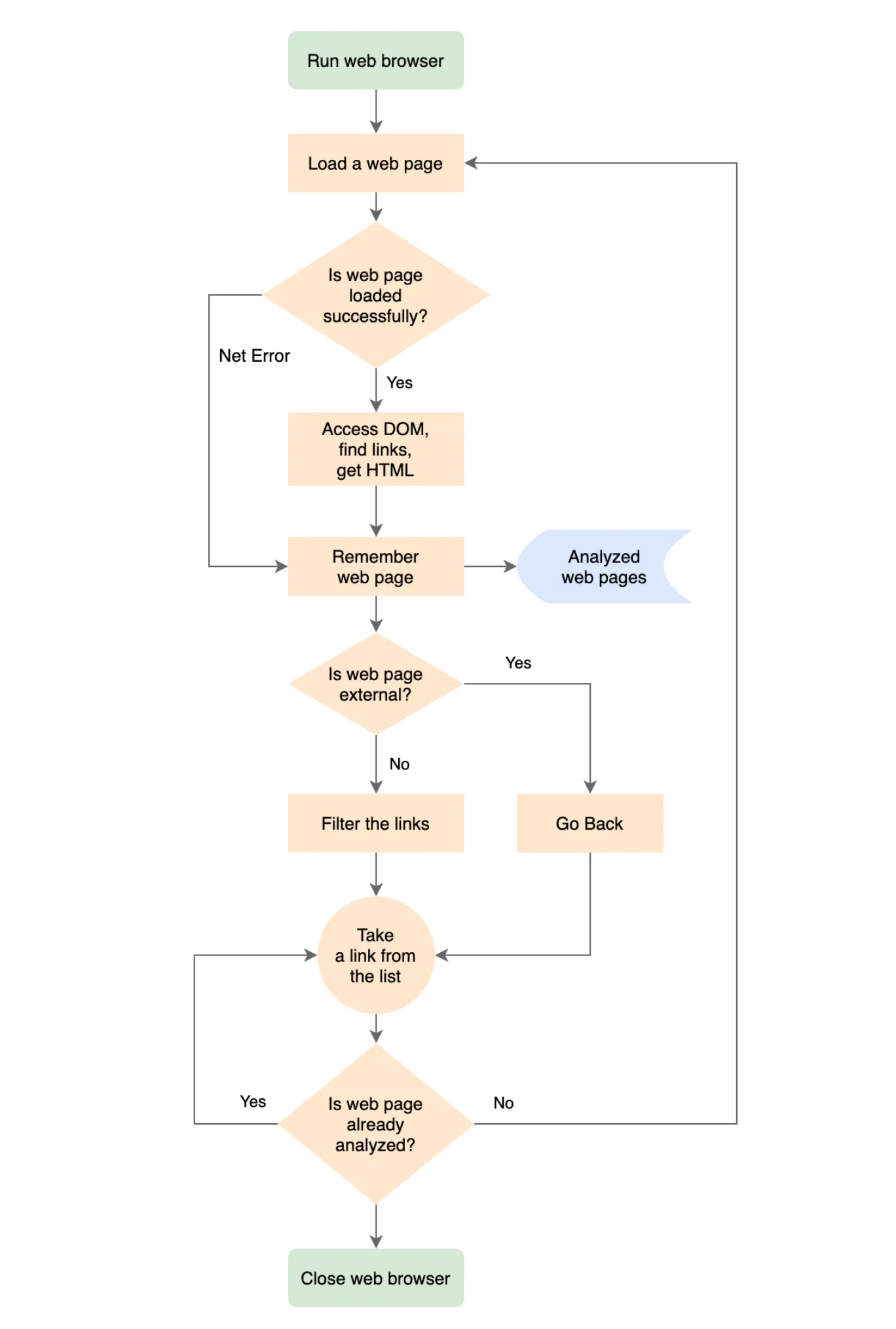
O algoritmo
Dadas todas as informações acima, vamos tentar pensar sobre como um programa baseado em um navegador web poderia funcionar.
- Iniciar o navegador Web.
- Carregar a página Web necessária.
- Se a página estiver carregada, acesse seu DOM e encontre todos os elementos âncora HTML. Para cada um dos , obter o valor HREF de cada componente. Desta forma, obterá todos os links na página.
- Se a página não foi carregada, lembrar-se do erro do servidor Web para a página.
- Lembrar-se da página processada.
- Se a página pertencer ao nosso sítio Web, filtre os links; remova os que não nos interessam, tais como links para subseções da página ou mailto:.
- Percorrer a lista de links recebidas.
- Para cada página da lista, siga os passos a partir da p. #1.
- Se for uma página externa, lembre-se dela, mas não analisar os seus links. Nós estamos apenas interessados nos links das páginas do nosso site Web.
- Depois de tratarmos de todas as páginas descobertas, concluímos a nossa navegação.
- Fechar o navegador Web.
- Percorrer todas as páginas analisadas e encontre as que têm links quebrados.
Segue-se o algoritmo do programa sob a forma de fluxograma.
Implementação
Vejamos como podemos implementar as principais etapas.
Iniciar um navegador Web:
Engine engine = Engine.newInstance(OFF_SCREEN);
Browser browser = engine.newBrowser();
Carregar uma página Web:
browser.navigation().loadUrlAndWait(url, Duration.ofSeconds(30));
Obtenção de acesso ao DOM e pesquisa de links:
browser.mainFrame().flatMap(Frame::document).ifPresent(document ->
// Recolha os links analisando o atributo HREF
// dos elementos HTML Anchor.
document.findElementsByTagName("a").forEach(element -> {
try {
String href = element.attributeValue("href");
toUrl(href, browser.url()).ifPresent(
url -> result.add(Link.of(url)));
} catch (IllegalStateException ignore) {
// O DOM de uma página web pode ser alterado dinamicamente
// a partir de JavaScript. O elemento DOM HTML que analisamos,
// pode ser removido durante a nossa análise. Nós não
// analisamos os atributos dos elementos DOM removidos.
}
}));
Obter a página HTML:
/**
* Devolve uma cadeia de caracteres que representa o HTML
* da página Web atualmente carregada.
*/
private String html(Browser browser) {
AtomicReference<String> htmlRef = new AtomicReference<>("");
browser.mainFrame().ifPresent(frame ->
htmlRef.set(frame.html())));
return htmlRef.get();
}
Exemplo da classe principal que analisa um site Web.
package com.teamdev.jxbrowser.examples.webcrawler;
import static com.google.common.base.Preconditions.checkNotNull;
import static com.teamdev.jxbrowser.engine.RenderingMode.OFF_SCREEN;
import com.google.common.collect.ImmutableSet;
import com.teamdev.jxbrowser.browser.Browser;
import com.teamdev.jxbrowser.engine.Engine;
import com.teamdev.jxbrowser.engine.EngineOptions;
import java.io.Closeable;
import java.util.HashSet;
import java.util.Optional;
import java.util.Set;
/**
* Uma implementação de Web crawler baseada no JxBrowser que
* permite descobrir e analisar as páginas Web, acessar seu conteúdo DOM e HTML, encontrar as links quebrados numa página Web
* etc.
*/
public final class WebCrawler implements Closeable {
/**
* Cria uma nova instância {@code WebCrawler} para o dado
* destino {@code url}.
*
* @param url o URL da página Web de destino que o rastreador
* iniciará a sua análise
* @param factory a fábrica utilizada para criar uma instância {@link
* WebPage} para os URLs interno e
* externo
*/
public static WebCrawler newInstance(String url,
WebPageFactory factory) {
return new WebCrawler(url, factory);
}
private final Engine engine;
private final Browser browser;
private final String targetUrl;
private final Set<WebPage> pages;
private final WebPageFactory pageFactory;
private WebCrawler(String url, WebPageFactory factory) {
checkNotNull(url);
checkNotNull(factory);
targetUrl = url;
pageFactory = factory;
pages = new HashSet<>();
engine = Engine.newInstance(
EngineOptions.newBuilder(OFF_SCREEN)
// Visite as páginas web no modo incógnito do Chromium
//.
.enableIncognito()
.build());
browser = engine.newBrowser();
}
/**
* Inicia o rastreador da Web e relata o progresso através do
* dado {@code listener}. O tempo necessário para analisar o sítio Web
* depende do número de páginas Web descobertas.
*
* <p>Esta operação bloqueia a execução da thread actual
* até o crawler parar de analisar as páginas Web descobertas.
*
* @param listener um listener que será invocado para reportar
* o progresso
*/
public void start(WebCrawlerListener listener) {
checkNotNull(listener);
analyze(targetUrl, pageFactory, listener);
}
private void analyze(String url, WebPageFactory factory,
WebCrawlerListener listener) {
if (!isVisited(url)) {
WebPage webPage = factory.create(browser, url);
pages.add(webPage);
// Notifica o listener que uma página web
// foi visitada.
listener.webPageVisited(webPage);
// Se for uma página web externa, não ir
// através dos seus links.
if (url.startsWith(targetUrl)) {
webPage.links().forEach(
link -> analyze(link.url(), factory,
listener));
}
}
}
/**
* Verifica se o {@code url} fornecido pertence a uma página da Web já
* visitada.
*/
private boolean isVisited(String url) {
checkNotNull(url);
return page(url).orElse(null) != null;
}
/**
* Retorna um conjunto imutável das páginas web que já foram
* analisadas por este crawler.
*/
public ImmutableSet<WebPage> pages() {
return ImmutableSet.copyOf(pages);
}
/**
* Devolve um {@code Optional} que contém uma página Web
* associada ao {@code url} fornecido ou uma opção vazia
* se não existir tal página Web.
*/
public Optional<WebPage> page(String url) {
checkNotNull(url);
for (WebPage page : pages) {
if (page.url().equals(url)) {
return Optional.of(page);
}
}
return Optional.empty();
}
/**
* Libera todos os recursos alocados e fecha o navegador web
* usado para descobrir e analisar as páginas web.
*/
@Override
public void close() {
engine.close();
}
}
O código completo do programa está disponível no GitHub.
Resultados
Se compilarmos e executarmos o programa, devemos obter o seguinte resultado:
https://teamdev.com/jxbrowser [OK]
https://teamdev.com/about [OK]
https://teamdev.com/jxbrowser/docs/guides/dialogs/ [OK]
https://teamdev.com/jxcapture [OK]
https://api.jxbrowser.com/7.13/com/teamdev/jxbrowser/view/javafx/BrowserView.html [OK]
https://spine.io [OK]
https://jxbrowser.support.teamdev.com/support/tickets [OK]
https://sos-software.com [OK]
...
Links mortos ou problemáticos:
https://www.teamdev.com/jxbrowser
https://www.shi.com CONNECTION_TIMED_OUT
http://www.comparex-group.com ABORTED
http://www.insight.com NAME_NOT_RESOLVED
https://www.swnetwork.de/swnetwork ADDRESS_UNREACHABLE
...
Processo terminado com o código de saída 0
Nuances, problemas e soluções
Eis algumas nuances encontradas durante a implementação e o teste desta solução em vários sites Web.
Muitos servidores Web estão protegidos contra ataques DDoS e os pedidos frequentes são rejeitados com o código de erro ABORTED. Para remover a carga do site Web e efetuar uma análise “educada”, é necessário utilizar um tempo limite. No programa, utilizamos um atraso de 500 ms. Infelizmente, mesmo com este atraso, o servidor Web rejeita os nossos pedidos.
Não desistimos e tentamos carregar a página em intervalos diferentes:
/**
* Carrega o {@code url} fornecido e espera até que a página web
* seja carregada completamente.
*
* @return {@code true} se a página Web tiver sido carregada
* com êxito. Se o URL fornecido estiver morto ou não tivermos conseguido
* carregá-lo em 45 segundos, devolve {@code false}.
*
* @implNote antes de cada navegação esperamos por {@link
* #NAVIGATION_DELAY_MS} porque o servidor Web pode abortar frequentemente
* pedidos de URL para se proteger de ataques DDoS.
*/
private NetError loadUrlAndWait(Browser browser, String url,
int navigationAttempts) {
// Todas as nossas tentativas para carregar o url fornecido foram rejeitadas (
// Desistimos e continuamos a processar outras páginas Web.
if (navigationAttempts == 0) {
return NetError.ABORTED;
}
try {
// O servidor Web pode abortar frequentemente pedidos de URL para
// se proteger de ataques DDoS. Utilizar um atraso
// entre pedidos de URL.
long timeout = (long) NAVIGATION_DELAY_MS
* navigationAttempts;
TimeUnit.MILLISECONDS.sleep(timeout);
// Carregar o URL fornecido e esperar até a página web
// estar completamente carregada.
browser.navigation()
.loadUrlAndWait(url, Duration.ofSeconds(30));
} catch (NavigationException e) {
NetError netError = e.netError();
if (netError == NetError.ABORTED) {
// Se o servidor Web abortar o nosso pedido, tente novamente.
return loadUrlAndWait(browser, url,
--navigationAttempts);
}
return netError;
} catch (TimeoutException e) {
// O servidor Web não respondeu no espaço de 30 segundos (
return NetError.CONNECTION_TIMED_OUT;
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
return NetError.OK;
}
O servidor Web pode efectuar um redireccionamento ao carregar a página. Quando carregamos um endereço, chegamos a outro. Nós podemos lembrar-nos de ambos os endereços, mas é vital parar e lembrar-se apenas do endereço solicitado na aplicação.
O servidor Web pode não responder a alguns pedidos de qualquer forma. Por conseguinte, ao carregar a página, é necessário utilizar o timeout para aguardar o download. Se a página não for carregada durante este tempo limite, você marcará a página como indisponível com o erro CONNECTION_TIMED_OUT.
Em algumas páginas da Web, o modelo DOM pode mudar imediatamente após o carregamento da página. Por conseguinte, ao analisar o modelo DOM, temos de lidar com a situação em que alguns elementos DOM podem não estar percorrendo a árvore DOM.
browser.mainFrame().flatMap(Frame::document).ifPresent(document ->
// Recolha os links analisando o atributo HREF dos
// elementos HTML Anchor.
document.findElementsByTagName("a").forEach(element -> {
try {
String href = element.attributeValue("href");
toUrl(href, browser.url()).ifPresent(
url -> result.add(Link.of(url)));
} catch (IllegalStateException ignore) {
// O DOM de uma página web pode ser alterado dinamicamente
// a partir de JavaScript. O elemento DOM HTML que analisamos,
// pode ser removido durante a nossa análise. Nós não
// analisamos os atributos dos elementos DOM removidos.
}
}));
Existem certamente muitas outras nuances do site na análise que pode encontrar. Felizmente, as capacidades do navegador Web permitem-lhe resolver a maioria dos problemas.
Conclusões
É possível criar um Java Crawler utilizando um navegador Web e, devido à nossa experiência, esta é uma forma mais natural de comunicação com o site Web. Muitas ferramentas SEO spider e Web Crawler no mercado de software profissional já utilizam há muitos anos estas soluções orientadas para as empresas com base nas capacidades do browser, o que prova a eficácia desta abordagem.
Pode experimentar e testar novos programas. Baixe o código-fonte do GitHub, faça edições para se adequar às suas necessidades.
Se tiver alguma dúvida sobre esta abordagem, basta deixar um comentário abaixo. Eu terei todo o prazer em responder a todas as suas perguntas em detalhes.